- Главная страница
- СППО
- Скачать задачи СППО
- ПРЗ на ЭВМ
- К списку занятий
- Python
- Скачать задачи по Python
- Информационные технологии в математике
- К программам
- Вспомогательная информация
- Карта клавиш
Главная страница
Лекция 2
Тема: Основные понятия теории информационных систем, введение в теорию баз данных
Дополнительная литература: Якубайтис Э. А. Информационные сети и системы (в книге дано определение информации).
Определение:
Информация – это совокупность фактов, явлений, событий, представляющих интерес и подлежащих регистрации и обработке. Таким образом, под информацией мы будем понимать любые сведения о каком-либо событии, процессе, объекте, которые являются предметом (результатом) операции восприятия, передачи, преобразования, хранения или использования (кратко, любые сведения, которые человек может понять).
Существует два вида информации – это первичная информация (необработанная) и обработанная.
Первичная информация – это выражение некоторого факта поведения, т.е. того, что характеризует определенное событие, ситуацию, состояние (первичная информация – это то, что характеризует определенное событие или объект).
Обработанная информация – это результат переработки первичной или ранее обработанной информации.
Три критерия качества информации:
- Актуальность – зависит от быстроты регистрации информации, от точности ее отнесения к определенному моменту времени или событию. Это свойство позволяет предвидеть события, т.е. сделать краткосрочный прогноз события. Это свойство также связано с понятием “срок старения информации” (некоторая информация актуальна только в короткий момент времени).
- Полнота информации – отражает желание обладать всей полезной информацией для анализа ситуации в целом. Существуют три способа отражения полноты информации:
1) Можно предусматривать накопление всех элементарных единиц информации относительно одного и того же объекта наблюдения.
2) Можно получить всю элементарную информацию, характеризующую явление в определенный момент времени.
3) Может представлять собой сочетание первого и второго способов.
Этот критерий (полнота информации) связан с понятием объема и количества информации.
- Точность – он дополняет второй критерий, гарантирует, что не произойдет никаких искажений, которые могли бы изменить один или несколько компонентов (объектов) информации.
Информация, предназначенная для управления компанией, может быть разделена на три составляющих

- Оперативная информация – нужна на нижнем уровне управления, является основой иерархии, автоматизируется в первую очередь. Т.е. когда создается БД, эта информация должна быть занесена в БД в первую очередь, остальная информация является выводом из оперативной информации. Крайне важно, чтобы она поступала незамедлительно (в задании на практике (на семинарах), оперативная информация представляется в виде таблиц в базе данных).
- Тактическая – получается путем обобщения оперативной информации. Предназначена для руководства среднего звена и получается в виде отчетов из бизнес-процессов, на основании отчетов и запросов по оперативной информации (взяли оперативную информацию, переработали, сделали отчеты, получили некоторые аналитические данные (аналитику), это и есть тактическая информация (в задании на практике – запрос или отчет)).
- Стратегическая – она предназначена для высшего руководства и получается в результате обработки оперативной и тактической информации. Содержит краткие сводки, отчеты, прогнозы, на ее основе осуществляется долгосрочное планирование, разработка бизнес плана предприятия в целом. В Access (на семинарах) – сводные диаграммы и сводные таблицы.
Определение:
Система – это объект, способный осуществлять хранение, обработку и передачу данных.
Рассмотрим внутренние свойства системы, которые характеризуются четырьмя основными аспектами:
- Системно-компонентный аспект, т.е. поиск ответов на вопрос, из чего, из каких компонентов состоит целое.
- Системно-структурный аспект, определяет качественную специфику системы, ее особенности, свойства, внутреннюю форму, взаимосвязи, взаимодействия
- Системно-функциональный аспект, состоит в проявлении функций системы, которые в свою очередь являются интегративным результатом функционирования компонентов системы. (все вместе функционируют)
- Системно-интегративный аспект, здесь главное - это сохранение качественной специфики системы (т.е. все компоненты взаимодействовали качественно и в полном объеме).
Определение:
Информационные системы – это совокупность:
- Функциональных процессов и связанных с ними информационных процессов, специфичных в конкретной предметной области.
- Средств, способов и методов, направленных на создание, сбор, хранение, анализ, обработку и передачу информации, существенно зависящих от специфики предметной области.
- Единого управления процессами, решения функциональных задач, а также информационными, материальными и денежными потоками предметной области.
(Т.е. важны функциональные процессы, средства, способы работы и единое управление процессами (всеми, включая денежные))
Если практика сдана, то зачет автоматом. Вроде так.
Информационные системы бывают следующих видов:
1) Справочно-поисковые
2) Управления в образовании
3) Автоматизированные информационные системы научных исследований
4) Системы автоматизированного проектирования (когда при введении координат, компьютер что-то рисует)
5) Геоинформационные системы (GPS навигаторы, Yandex карты)
6) Экспертные системы
7) Гипертекстовые информационные системы
Компоненты информационной системы:
1) База данных – это совокупность данных, обладающих следующими свойствами
- Интегрированность, направленная на решение общих задач одной предметной области (т.е. база данных создается только по одной конкретной области)
- Модульность, структурированность, отражающая некоторую часть реального мира
- Независимость описания данных от прикладных программ (т.е. неважно, на какой системе управления базами данных (СУБД) мы будем реализовывать данную базу данных (БД))
2) Система управления базами данных (СУБД) – это пакет программ, позволяющий
- Обеспечить пользователя языковыми средствами описания и манипулирования данными.
- Обеспечить поддержку логических моделей данных
- Обеспечить операции создания и манипулирования логическими данными и одновременное отображение этих операций над физическими данными.
- Обеспечить защиту и целостность данных (целостность, это означает, что если есть взаимосвязанные объекты, то при удалении объекта, те объекты, которые были связаны с ним, тоже удаляются (короче, установка связей)).
3) Администратор базы данных – это специалист или группа специалистов, занятых обслуживанием пользовательской базы данных (БД) (его задачи - защитить БД, создать запросы и отчеты, проследить, что все запросы и отчеты работают (короче, создать или настроить базу данных))
4) Словарь данных – это специальная система в базе данных, которая предназначена для хранения единообразной и централизованной информации обо всех ресурсах данных конкретной базы данных (могут быть справочники в базе данных, которые могут дополняться или оставаться неизменными)
5) Вычислительная система – это серийно выпускаемая ЭВМ, либо несколько ЭВМ, соединенных каналами связи в вычислительную сеть.
6) Обслуживающий персонал – это пользователи базы данных. От качественной работы пользователей, зависит правильная работа информационной системы.
Рассмотрим классификацию баз данных по нескольким критериям.
По функциональному назначению БД делятся на три основных вида
- Фактографические – содержат формализованные (четко сформулированные) данные об объектах фиксированной длины. Любая запись в такой БД имеет свой ключ. (На семинарах мы строили таблицы, это фактографические БД, т.к. там была фиксированная длина каждой записи и там был ключ)
- Документальные – содержат неформализованные тексты документов (хранение и поиск документов – основная задача для документальных БД). Для каждого документа создается поисковый образ, содержащий фиксированный определенный набор дескрипторов (описаний) и по этим дескрипторам находится тот или иной документ
- Интеллектуальные – содержат формализованные сведения из любых областей знаний (данный вид БД возник в связи с возникновением ИИ)
По отношению к использованию технический средств БД можно разделить на два вида:
- Локальные – размещаются в памяти одного ПК
- Распределенные – размещаются на нескольких ПК. (если рассмотреть совокупность локальных баз данных (т.е. соединенных сетью), то это будет распределенная БД)
Любая БД имеет модель данных
Модель данных – это интегрированный набор понятий для описания данных, связи между ними и ограничений, накладываемых на данные в некоторой организации.
Три основных модели БД:
- Иерархическая (классический пример – файловая система, где есть родитель, потомки, потомки наследуют все свойства родителя, а если у потомка появляется свое уникальное свойство, то родитель этим свойством не обладает)
- Сетевая
- Реляционная (от слова relation - отношение), в этой теории говорится, что данные проще всего представить в виде таблицы. Столбцы соотносятся со строчками - самое простое отношение, таблицы могут быть взаимосвязаны между собой в одной БД.
Определение:
Реляционной моделью называется способ рассмотрения данных посредством таблиц и для способа работы с такими представлениями, посредством операторов
Концепция реляционной модели была предложена в 1970 году, ученым Коддом.
Некоторые определения, связанные с реляционной моделью баз данных:
Отношение – удобно представляется в виде двумерной таблицы.
Строки таблицы называют записями
Столбцы называют атрибутами
Кортеж – это соответствующие строки таблицы.
Количество кортежей называется координальным числом.
Количество атрибутов называется степенью
Таблицы в теории реляционных моделей называются сущностями.
Поле – столбец (в Access).
Пример 1:
Когда мы создавали базу данных “студенты и задания”, мы создали две таблицы (сущности). После чего мы определяли атрибуты каждой сущности (столбцы каждой таблицы). Когда мы каждую сущность укладываем в качестве таблицы в базу данных, то мы получаем таблицу со строчками, которые называются записями и столбцами (атрибутами, полями).
Пример 2:
Если в качестве сущности выбрать автомобиль, то его атрибутами будут
Цвет, марка, регистрационный номер, пробег, тип кузова, мощность, год выпуска и т.д.
Определение:
Первичный ключ – это уникальный идентификатор для таблицы, т.е. столбец или такая комбинация столбцов, что в любой момент времени не существует двух строк, содержащих одинаковые значения (т.е. это уникальный идентификатор, такой, что по нему однозначно определяется запись).
Пример: на семинарах в роли первичного ключа был счетчик.
В жизни уникальным идентификатором является номер студенческого билета, ИНН – уникальный идентификатор человека в налоговой службе.
Определение:
Домен – общая совокупность значений, из которой берутся настоящие значения для определенных атрибутов определенного отношения (список значений, откуда берутся значения для столбцов некоторой таблицы, например, для столбца имени домен представляет собой следующий список: Анна, Наталья, Федор, Петр, Алина, Александр и т.д.).
Лекция 3
Таблица соответствий
Формальный реляционный термин |
Неформальный эквивалент |
Отношение |
Таблица |
Кортеж |
Строка или запись (строка таблицы, уже заполненная) |
Атрибут |
Столбец или поле |
Координальное число |
Количество строк |
Степень |
Количество столбцов |
Первичный ключ |
Уникальный идентификатор |
Домен |
Общая совокупность допустимых значений |
Архитектура базы данных
Архитектура базы данных – это уровни представления данных.
Уровни представления данных:
Внешнее представление данных – совокупность требований к данным, проектируемой базы данных. Внешнее представление рассматривается с точки зрения конечного пользователя и прикладного программиста. (Внешний интерфейс – для пользователя, программист – реализует запросы и кнопки (т.е. реализует внешний интерфейс))
Концептуальное представление данных – отображение знаний о предметной области, разрабатываемой базы данных или совокупность всех требований к данным, полученным от пользовательских внешних представлений. Элементы предметной области проектируемой базы данных, их свойства и связи между собой называются элементарными единицами концептуальной схемы.
Внутреннее или физическое представление данных – это организация хранения данных на физических носителях. Выражает точку зрения на представления данных системных программистов. Важную роль при данном представлении данных играет язык манипулирования данными. (Англ. DML – date manipulation language). Язык манипулирования данными – это формальный язык, предназначенный для манипулирования содержимым базы данных.
Для каждого уровня существует своя модель (рассмотрим три взаимосвязанных модели данных):
- Внешняя или функциональная модель данных – отображает представления каждого типа пользователей проектируемой информационной системы.
- Концептуальная модель данных – отображает логическое представление данных независимо от типа выбранной СУБД
- Внутренняя модель данных – отображает концептуальную схему определенным образом, понятным выбранной СУБД
Тема: Использование Access для проектирования реляционной базы данных
Access – программное средство, спроектированное для создания многопользовательских приложений, где файлы базы данных являются разделяемыми ресурсами сети. В этом программном средстве реализована защита от несанкционированного доступа. Access имеет собственную уникальную структуру: создания базы данных в рамках одного файла. Реализована возможность импорта и экспорта данных (импорт таблиц из Excel, экспорт тоже в Excel или в Word).
Объекты Access:
Таблицы – создаются пользователем для хранения данных. Для любого объекта модели данных создается одна таблица.
Формы – предназначены для ввода и просмотра взаимосвязанных данных БД на экране в удобном виде (т.е. для пользователя). Формы можно распечатывать.
Запросы – создаются пользователем для выборки нужных данных из одной или нескольких связанных таблиц. Он может формироваться с помощью двух путей:
- Запросы по образцу (Query By Example (QBE))
- С помощью инструкций языка SQL (structured query language – язык структурированных запросов)
С помощью запросов мы можем обновить, удалить, добавить данные в существующей таблице. Также, с помощью запросов можно создавать новые таблицы.
Отчеты – используются для формирования выходного документа для печати.
Макросы – содержат описание действий, которые должны быть выполнены в ответ на некоторое событие.
Модули – содержат программы на языке Visual Basic for Application, которые разрабатываются пользователем для реализации нестандартных процедур и функций при создании приложений.
Функции Access:
Бывают основные и дополнительные.
Среди основных выделим 4.
Основные
- Организация данных – включает в себя создание таблиц и управление ими.
- Связывание таблиц и осуществление доступа к данным. Связывание таблиц по совпадающим значениям полей.
- Добавление и изменение данных – эта функция требует разработки и реализации представления данных в табличном виде. В Access для этого могут быть использованы формы.
- Презентация данных – позволяет создавать любые отчеты на основе данных, хранящихся в таблице или отображенных в результате запроса.
Дополнительные функции – макросы, модули, защита базы данных, средства печати и другие.
Основные режимы Access:
- Режим запуска – в этом режиме мы можем осуществлять сжатие, шифрование, дешифрование и некоторые другие операции без открытия базы данных.
- Режим конструктора – в этом режиме могут создаваться и модифицироваться структуры таблиц и запросов, разрабатываться формы, формироваться отчеты.
- Режим выполнения – в этом режиме в главном окне Access выводятся окна объектов базы данных (например, функция просмотра отчетов).
Работа с таблицами в Access
С точки зрения Access база данных – это совокупность структурированных, взаимосвязанных данных и методов, обеспечивающих добавление, изменение, выборку и отображение данных.
Создание таблиц возможно в трех режимах:
- В режиме конструктора, где пользователь вводит самостоятельно номера полей и выбирает типы данных, определяет длину полей (размер), свойства полей (маски ввода). Имя поля не может содержать некоторые символы, например, точка. Пробелы в имени поля в Access допускаются.
- Режим мастера – можно подобрать готовую таблицу из представленного перечня.
- Режим непосредственного ввода данных (все данные будут текстовыми, впереди встанет счетчик).
Типы данных в Access:
- Текстовый – это текст или число, не требующие расчетов. Размер поля не превышает 255 символов.
- MEMO – предназначен для хранения больших текстовых данных (до 64000 символов).
- Числовой – это байт (логический), целое число, длинное целое число, знаковое число. К данным этого типа мы можем отнести как тип счетчик, так и логический тип (в Access счетчик и логический типы выделены отдельно).
- Дата/время – форматирование даты
- Поле объектов OLE – рисунки, звукозаписи и другие типы данных. Такое поле не может быть ключевым и не может быть проиндексировано (оно не может участвовать в связке, которая дает возможность поиска информации).
- Гиперсвязи (гиперссылки) – содержат адреса WEB-страниц.
Связи
Связи между таблицами должны быть в виде не замкнутого графа (дерева). Т.е. количество связей (ребер) должно быть на 1 меньше, чем таблиц (вершин).
Виды связей:
- Один к одному – когда одна запись в главной таблице может иметь не более одной записи в связной таблице. В таблицах ключевые поля должны быть уникальны.
- Многие к одному – когда одной или нескольким записям в главной таблице соответствует одна запись в связной таблице.
- Один ко многим – когда одной или нескольким записям в связной таблице соответствует одна запись в главной таблице.
- Многие ко многим – нескольким записям из главной таблицы соответствует несколько связей из связной таблицы. Т.е. одной связи из главной таблицы соответствует несколько связей из связной таблицы и наоборот.
Для всех типов связи предусматривается:
- Автоматическое обеспечение целостности данных – это когда невозможно ввести в поле связной таблицы значения, не содержащиеся в ключевом поле главной таблицы.
- Не допускается удаление записей из главной таблицы, если существуют связанные с ней записи в подчиненной таблице.
- Невозможно изменить значение ключевого поля в главной таблице, если имеются данные, связанные с этой записью.
От которой таблицы ведется – главная, к которой таблице ведется – связная.
Лекция 4
Работа с запросами в Access
Запросы создаются пользователем для выборки данных. Иначе – для выборки данных из таблицы.
Виды запросов:
- Запрос на выборку
- Запрос на обновление
- Запрос на удаление (таблиц)
- Запрос на добавление
Таким образом, с помощью запросов мы можем выбирать, обновлять и добавлять данные в таблицу.
В Access есть два способа создания запросов:
- Запросы по образцу (QBE – Query By Example)
- Запросы, которые создаются при помощи языка SQL
Способы создания запросов (в Access):
- Создание запроса с помощью конструктора
- Режим редактора выражений языка SQL
- Программный способ создания запросов с помощью объектов
Запросы по образцу – этот вид запросов предназначен для выборки данных из базы.
Есть 4 типа запросов по образцу (при нажатии на кнопку создать):
- Запрос на выборку – отображает данные одной или нескольких связанных между собой таблиц.
- Перекрестные запросы – собирает данные из одной или нескольких таблиц для анализа данных. В дальнейшем на основе перекрестных запросов строятся диаграммы.
- Запросы на изменение – запросы на изменения, вносим новые данные в таблицу, вносим изменение или вообще создаем новую таблицу, можем добавлять, удалять записи
- Запросы с параметрами – когда нужно ввести дополнительный параметр (всплывающее окно)
Новый запрос в Access может быть создан следующими способами:
- Мастер запросов
- Конструктор запросов – отсюда можно переключаться в режим SQL
Более сложные условия можно делать с помощью построителя выражений. Он вызывается в режиме конструктора.
Выражения, вводимые с помощью режима SQL, могут содержать следующие компоненты:
- Операторы:
- Арифметические
- Логические (например, and)
- Соединения
- Идентификации (помечаются восклицательным знаком (!), это означает принадлежность той или иной таблице) – создают однозначные имена в БД для объектов
- Присваивания
- Сравнения
- И другие, например, is, in, between (для связки дат, если некоторая дата содержится между двумя другими, то этот оператор возвращает true)
- Константы:
- Числовые
- Текстовые
- Дата
- Время
- Идентификаторы – используются для именования объектов
- Функции. В Access определено около 140 функций, они сгруппированы по назначению. Назначения:
- Дата/время
- Текстовые
- Преобразования типов
- Математические
- Финансовые
- Смешанного типа
- Статистические
Формы
Формы предназначены для того, чтобы упростить интерфейс пользователя.
Отчеты
Отчеты нужны для того, чтобы вывести результаты выполнения запросов на печать.
Первичный и внешний ключ
Ключ – это минимальный набор атрибутов (столбцов), по которым можно однозначно найти требуемый экземпляр сущности (таблицы).
По простому:
Минимальный набор столбцов, по которым однозначно можно найти запись в таблице.
Минимальный – это означает, что если из минимального набора атрибутов мы удалим один атрибут, то из остаточных атрибутов мы не сможем найти экземпляр сущности.
Каждая сущность обладает хотя бы одним возможным ключом. Хотя бы одним – это означает один или несколько. Поэтому, один из этих возможных ключей мы принимаем за первичный ключ.
Предпочтения к выбору первичного ключа:
- При выборе первичного ключа мы отдаем предпочтение не составному ключу.
- Не следует использовать ключи с длинными текстовыми значениями.
- Не допускается, чтобы первичный ключ принимал неопределенное значение.
- Должна присутствовать уникальность первичного ключа. Т.е. если мы попытаемся ввести ранее введенное значение в это поле, то у нас выскочит ошибка.
Пример:
В базе данных видеотека в таблицах страны и жанры мы делаем первичными ключами поля Страна и Жанр соответственно, т.к. страны и жанры не повторяются.
Внешние ключи
По внешнему ключу мы можем выстраивать взаимосвязи между таблицами.
Пример:
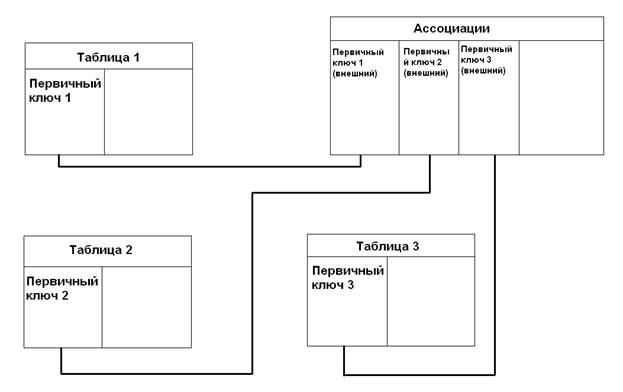
Если сущность С связывает сущности A и B, то она должна включать внешние ключи, соответствующие первичным ключам сущности A и B.
Пример:
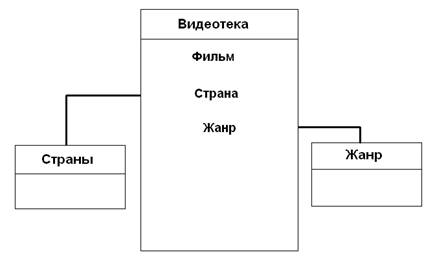
В данном примере поля Страна и Жанр в таблице библиотека являются внешними ключами для таблиц Страны и Жанр.
Для каждого внешнего ключа необходимо решить три вопроса:
- Может ли данный внешний ключ принимать неопределенные значения (например, 0 или пустые). Если данное поле может принимать такие значения, то его нельзя взять в качестве внешнего ключа.
- Что должно случиться при попытке удаления целевой сущности, на которую ссылается внешний ключ. Существуют три возможности:
- Каскадирование. Например, у нас есть таблицы поставки и поставщики (см. рис. ниже), в таблице “Поставщики” поле поставщик – первичный ключ, а в таблице “Поставки” поле поставщик – внешний ключ. Если мы удаляем поставщика, то из поставок удаляются все товары, которые связаны с поставщиком, т.е. происходит каскадное удаление данных из связных таблиц.
- Ограничиваются. Например, удаляются те поставщики, которые не осуществляли поставок, иначе удалить нельзя. Если в таблице “Поставки” есть хотя бы одна поставка от удаляемого поставщика, то его удалить нельзя.
- Устанавливаются (внешний ключ устанавливается в неопределенное значение и затем поставщик удаляется, но такая операция не сможет быть выполнена). Но если внешний ключ не может содержать неопределенное значение, то такая операция будет недопустима.
- Что должно происходить при попытке обновления первичного ключа целевой сущности, на которую ссылается внешний ключ. При этом происходят три возможности:
- Каскадируется. Например, при обновлении первичного ключа в поставщиках, обновляется и внешний ключ в поставках.
- Ограничивается. Может обновляться лишь тот поставщик, который не участвовал в поставках. Если поставщик участвовал в поставках, то его первичный ключ обновить нельзя.
- Устанавливается. Для всех поставок, у которых значение данного поставщика устанавливается неопределенное значение внешнего ключа, а затем обновляется первичный ключ поставщика.
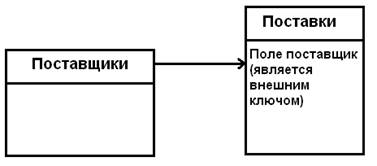
Рис.
Т.о. для каждого внешнего ключа проектировщик базы данных должен специфицировать (установить специфику /*выделить особые черты, характеристики*/) не только поле или комбинацию полей, составляющих внешний ключ, но и ответы на указанные вопросы (“что происходит, если”, т.е. предусмотреть эти три ограничения).
Ограничение целостности – под целостностью мы понимаем правильность данных в любой момент времени. Но это не всегда возможно сделать.
Поддержание целостности базы данных рассматривается, как защита от неверных изменений или разрушений (речь идет о защите от дурака (ввода некорректных данных)).
Выделяют три группы правил целостности:
- Целостность по сущностям.
- Целостность по ссылкам.
- Целостность, определяемая пользователем.
Чаще всего контролируются:
- Уникальность тех или иных атрибутов
- Диапазон значений. Например, оценка может быть от 2 до 5, иначе быть не может.
- Принадлежность набору значений (выбор из предложенных значений)
Почему проект базы данных может быть плохим:
- Избыточность – данные почти всех столбцов многократно повторяются. Например, в первой лабораторной работе не было связи между таблицами и в результате два раза приходилось хранить фамилию, имя и отчество студентов.
- Потенциальная противоречивость – это происходит из-за избыточности данных. Например, когда данные повторяются во всех таблицах, мы поменяли значение в одной таблице, а в другой таблице значение такого же поля не поменялось
- Аномалии включения (например, идут поставщики, которые поставляют поставки и есть поставщик, который ничего не поставляет и его товары никак не могут быть использованы).
- Аномалии удаления – если необходимо удалить некоторые данные по поставщикам, то было бы неплохо удалить данные поставщика (те продукты, которые поставляет поставщик).
Нормализация и функциональные зависимости
Процесс нормализации – это разбиение таблицы на две или более, обладающих лучшими свойствами, при включении, изменении и удалении данных.
Цель нормализации – получить такой проект базы данных, в котором каждый факт появляется только в одном месте. Исключена избыточность информации (это делается для того, чтобы убрать противоречивость).
Всякая нормализованная таблица (т.е. та, в которой отсутствуют повторения) автоматически считается таблицей в первой нормальной форме.
Нормальных форм несколько.
Если мы рассматриваем процесс нормализации, то мы рассматриваем функциональные и многозначные зависимости между полями таблиц, т.е. для того, чтобы провести процесс нормализации – нам необходимо найти зависимости между полями таблиц и, может быть, сделать разбиение таблицы на две.
Процесс нормализации таблиц – это процесс разбиения на несколько табличек по определенному принципу (ищутся связи и зависимости между полями таблиц и, исходя из этого, делаются разбиения).
Два вида зависимостей:
- Функциональная – если поле B функционально зависит от поля A той же таблицы в том случае, если в любой заданный момент времени для каждого из различных значений поля A существует только одно из различных значений поля B.
- Многозначная – поле A многозначно определяет поле B, если для каждого значения поля A существует определенное множество значений поля B.
Например, табличка (иллюстрирует многозначные зависимости – один автор написал две книги (Автор 1 написал Книгу 1 и Книгу 2) и одну книгу написали два автора (Книгу 1 написали Автор 1 и Автор 2)):
Дисциплина |
Автор |
Книга |
Информатика |
Автор 1 |
Книга 1 |
Информатика |
Автор 1 |
Книга2 |
Информатика |
Автор 2 |
Книга 1 |
Информатика |
Автор 3 |
Книга 2 |
Эту таблицу необходимо нормализировать (вынести дисциплину в отдельную таблицу, авторов вынести в отдельную таблицу, книги тоже вынести в отдельную таблицу).
Лекция 5
Тема: CASE-средства.
CASE – аббревиатура, которая обозначает в переводе на русский язык “Компьютерная Инженерия Информационной Системы”.
CASE-технология – это совокупность методологий (правил) анализа, проектирования, разработки и сопровождения сложных систем программного обеспечения (ПО).
CASE-средства – это инструментарий, позволяющий автоматизировать процесс проектирования и разработки ПО.
Признаки программного продукта, как CASE-средства:
- Поддержка методологий структурного анализа и проектирования. Существуют два основных подхода для разработки программного обеспечения для информационных систем (существуют два способа декомпозиции (разделения) для информационных систем и, исходя из этих разных способов декомпозиции, реализуются эти подходы):
- Функционально-модульный (структурный) – в основе лежит принцип функциональной декомпозиции (разделения) при котором структура системы описывается в терминах иерархии функций и передачи информации между элементами.
- Объектно-ориентированный подход – использует объектную декомпозицию, при этом структура системы описывается в терминах объектов и связей между ними, а поведение системы описывается в терминах обмена сообщениями между ними.
На сегодняшний день выбирается методология структурного анализа (она является основной).
Методы структурного подхода базируются на ряде общих принципов, базовыми из которых являются:
- Разделяй и властвуй
- Иерархическая упорядоченность
Это базовые принципы, однако, они являются не единственными. Существует ряд других основных принципов, на которых строится методология структурного анализа.
Среди основных принципов мы можем указать следующие:
- Принцип абстрагирования – выделяем существенные моменты (аспекты) системы и отвлекаемся от несущественных моментов.
- Формализация – это строгий методический подход к решению проблемы.
- Упрятывание – любая часть системы знает только необходимую информацию.
- Концептуальная общность (концептуальность, концепт – единая философия) – должна быть единая философия на всех этапах жизненного цикла ПО.
- Принцип полноты (полнота) – должен быть контроль за присутствием лишних элементов.
- Принцип непротиворечивости – обоснованность и согласованность элементов.
- Принцип логической независимости – логическая независимость от физического проектирования. Т.е. мы проектируем до того, как мы спустимся на уровень базы данных (физическое проектирование – проектирование на базе данных). СУБД на данном этапе не является ключевым моментов.
- Независимость данных – модели данных должны быть независимы от процессов их логической обработки (т.е. не важно, как мы будем программно их обрабатывать).
- Структурирование данных – данные должны быть структурированы и иерархически организованы.
- Доступ конечного пользователя – должен быть объяснен (как конечный пользователь БД должен получать доступ к базе данных без участия программы).
В структурном подходе чаще всего используются три группы средств, которые описывают функциональную структуру системы и отношения между данными в системе. Каждой группе средств строится определенный вид модели (диаграммы).
Самые распространенные модели:
- DFD (date float diagramms) – диаграмма потоков данных
- SADT (structure analysis and design technologies) – метод определения анализа и проектирования. В этом методе указываются модели и соответствующие этим моделям функциональные диаграммы.
- ERD – диаграмма сущность-связь.
Конкретный вид перечисленных диаграмм зависит от интерпретации и стадии жизненного цикла ПО.
Жизненный цикл программного обеспечения определяется, как период времени, который начинается с момента принятия решения о необходимости создания ПО и заканчивается в момент его полного изъятия из эксплуатации. Таким образом, этапы жизненного цикла ПО мы можем определить по пунктам.
Этапы жизненного цикла ПО:
- Формирование требований к программному обеспечению
- Проектирование
- Реализация – внедрение проекта
- Тестирование – проверка работоспособности проекта
- Ввод в действие – передача всех данных заказчику
- Эксплуатация и сопровождение
- Снятие с эксплуатации
Именно эти стадии жизненного цикла должно проходить любое ПО. Будь то это БД или какая-то программа.
Рассмотрим стадию формирования требований к ПО (CASE-средства используются именно на этом этапе)
SADT модели и DFD модели используются для построения модели AS-IS и модели TO-BE, т.е. для построения моделей, отражающих существующую и предлагаемую схему бизнес-процессов организации и взаимосвязей проектирования, а также разработки программного обеспечения. Часто это применяется для создания ПО для оборонных систем.
Метод SADT
Метод SADT представляет собой совокупность правил и процедур, предназначенных для построения функциональной модели объекта какой-либо предметной области.
Основывается на функциях системы или на ее предметах (иначе – объектах). Соответствующие модели, которые получаются в SADT моделировании, называются функциональными или моделями данных.
Основным рабочим элементом модели является диаграмма. Эта диаграмма представлена в древовидной иерархической структуре.
Чем выше уровень диаграммы, тем она менее детализирована.
В состав диаграммы входят блоки, которые служат для отображения (отражения) функций системы и дуги – связи между функциями.
На одной диаграмме следует отображать от трех до шести блоков. Каждая строка блока имеет строго определенное значение. Нарисуем данный блок.
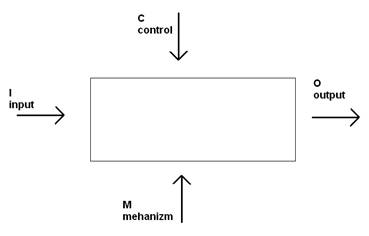
Данная модель называется ICOM (Input Control Output Mehanizm).
Эта модель отражает определенные принципы функционирования системы. Входы преобразуются в выходы, управление (control) ограничивает или предписывает условие выполнения.
Механизмы описывают, за счет чего выполняются преобразования.
Дуги – это наборы данных, которые маркируются текстом на естественном языке (на русском).
Блоки на диаграмме размещаются в виде ступенчатых схем в соответствии с их доминированием, блоки влияют друг на друга. Они должны быть пронумерованы в соответствии с доминированием. Номера блоков служат однозначными идентификаторами для функций и автоматически организуют эти функции в иерархическую модель.
Взаимовлияние блоков выражается либо в пересылке выхода другой функции (выход пересылается в другую функцию) для дальнейшего преобразования, либо в выработке управления информацией, предписывающей, что именно делать другой функции.
В SADT существует 5 типов взаимосвязей между блоками:
1) Управление
2) Вход-выход
3) Механизм
4) Обратная связь по управлению
5) Обратная связь по выходу
Дуги в SADT изображают наборы данных, поэтому они могут разветвляться и соединяться вместе любым образом.
/*Блоки на одной модели образуют иерархическую структуру, рассматриваем один блок и начинаем раскрывать его функциональную значимость, потом рассматриваем другой блок и раскрываем его функциональную значимость и т.д.*/
DFD модель
Модель DFD – это диаграмма потоков данных. Является основным средством моделирования функциональных требований к проектируемой системе.
Используются две различные составляющие, они соответствуют двум методам:
- Метод Йордана
- Метод Гейна-Сорсопа
Основные символы, которые используются в данной модели:
 - обозначение потока
- обозначение потока - процесс. Это функция в которой входные данные преобразуются в выходные.
- процесс. Это функция в которой входные данные преобразуются в выходные. - хранилище. Запись, которая дает нам возможность отражать хранение данных.
- хранилище. Запись, которая дает нам возможность отражать хранение данных. - внешняя сущность. Источник или приемник системных данных.
- внешняя сущность. Источник или приемник системных данных.
В DFD диаграммах существует так называемая контекстная диаграмма. Это специальный вид DFD диаграммы, который моделирует систему наиболее общим образом, отражает интерфейс (взаимосвязь) системы с внешним миром. Любой проект должен иметь одну контекстную диаграмму.
Для обеспечения декомпозиции данных в DFD добавляются следующие типы объектов:
- Групповой узел – служит для разъединения и соединения потоков.
- Узел предок – служит для детализации
- Неиспользованный узел – служит тогда, когда требуются не все элементы, входящие в узел потока
- Узел изменения имени
- Текст – может находиться в любом месте диаграммы
Обозначим рекомендации по построению модели:
- На диаграмме может быть изображено от трех до шести-семи процессов.
- Не загромождать диаграммы не существенными на данном уровне деталями
- Декомпозиция (разделение) потоков данных должна осуществляться параллельно с декомпозицией (разделением) процессов.
- Имена процессов и потоков должны отражать их сущность
- Отделять управление структурой от обработки структур, т.е. процессов (т.е. отделять управление структурой от процессов).
ERD диаграмма.
Цель моделирования данных состоит в обеспечении разработчика информационной системы концептуальной (стратегической) схемой базы данных.
ERD модель строится на этапе инфологического проектирования.
Строится либо одна модель, либо несколько локальных моделей.
ERD диаграммы были введены в 1976 году Питером Ченном.
Базовые понятия ERD диаграммы:
- Сущность – это реальный, либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области. Например, город. У каждой сущности есть экземпляр. У города мы можем выделить экземпляр: Москва, Питер, Лондон и т.д.. Каждая сущность должна обладать уникальным идентификатором.
Виды сущностей: - Независимая (изображается прямоугольником) – представляет независимые данные, которые всегда присутствуют в системе, при этом отношения с другими сущностями, могут, как существовать, так и отсутствовать.
- Зависимая – данные, зависящие от других сущностей системы.
- Ассоциированная (связанная) – представляет данные, которые ассоциируются (связываются) с отношениями двумя или более сущностей. Каждая сущность может обладать любым количеством связей.
Связь – это поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области.
Типы связей: - Неограниченная, т.е. отношение, которое существует всегда до тех пор, пока существуют относящиеся к нему сущности
- Ограниченная – представляет собой условие отношения между сущностями
- Существенно ограниченные – существует только, когда сущности взаимосвязаны (т.е., когда связь взаимна). Типы отношений, которые мы можем выделить: один к одному, один ко многим, многие к одному, многие ко многим.
- Атрибут – поименованная характеристика сущности, его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущности.
Например: Цвет – атрибут сущности. Может быть характеристикой для различного типа сущностей: собака, самолет, автомобиль, здание. - Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности.
Существуют три типа ключей: - Первичный ключ
- Внешний ключ
- Альтернативный ключ – каждая сущность должна обладать хотя бы одним первичным ключом. При существовании нескольких возможных ключей, один из них обозначается, как первичный, а остальные, как альтернативные.
- Абстрагирование
- Инкапсуляция
- Модульность
- Иерархия
- Три дополнительных элемента
- Типизация
- Параллелизм – поддержка параллельных процессов
- Устойчивость
- Полиморфизм – способность класса принадлежать более чем одному типу
- Наследование – это построение новых классов на основе существующих с возможностью добавления и переопределения данных и методов.
- Язык моделирования
- Описание процесса моделирования
- Диаграмма компонентов
- Диаграмма размещения
- Инфологическое проектирование
- Датологическое проектирование (от слова data – данные)
- Инфологическое проектирование
- Датологическое проектирование – спускаемся на уровень данных.
- Физическое проектирование – проектирование на уровне СУБД
- Опытная эксплуатация
- Идентификация сущностей, т.е. выделение объектов рассматриваемой предметной области
- Определение атрибутов сущности (выделение существенных свойств объектов)
- Установление всех связей между сущностями (структурные, иерархические, запросные)
- Нормализация модели (поговорим об этом попозже)
- Минимизация числа сущностей (таблиц)
- 1НФ
- 2НФ
- 3НФ
- 3ФБК (нормальная Форма Бойса Кодда)
- 4НФ
- 5НФ
- Аномалия вставки
- Аномалия удаления
- Аномалия обновления
- Выравнивание – пустые ячейки заполняются дубликатами, неповторяющихся данных (??? Зачем нам заполнять дубликатами неповторяющихся данных, если нам надо избавиться от повторяющихся данных?);
- Назначается ключ таблицы, а повторяющиеся группы помещаются в отдельную таблицу вместе с копией ключа в исходной таблице.
- Идентификация сущностей
- Определение атрибутов сущностей
- Минимизация сущностей.
- Сущность должна иметь уникальное имя
- Сущность обладает одним или несколькими атрибутами
- Совокупность атрибутов сущности с конкретными значениями однозначно идентифицируют каждый экземпляр сущности
- Каждая сущность может обладать любым количеством связей с другими сущностями
- Если все атрибуты рассматриваемой сущности полностью присутствуют в какой-либо другой, то рассматриваемая сущность является избыточной и должна быть ликвидирована.
- Если имеется несколько сущностей с одинаковыми первичными ключами, то возможно объединение этих сущностей в одно в том случае, если в новой сущности может быть введен общий атрибут, ограничивающий смысл всех исходных сущностей. Можно ли пример? Ключ оставляем, а остальное сливаем в одну таблицу, добавляем атрибут, чтобы не было противоречий
- Если некоторая сущность является проекцией одной сущности-связи, то она может быть объединена с другими проекциями. Т.е. несколько проекций одной сущности-связи можно объединить в одно (что такое проекция сущности – дубликат, и сущность связь – связывает две сущности?)
- Если в модели есть сущности, имеющие одинаковый первичный ключ, и они имеют взаимно однозначное соответствие (это как? если они одинаковые), то их можно объединить в одну, в том случае, если периодичность (что за периодичность?) изменения первичных ключей во всех сущностях одинакова.
- Инфологическую модель предметной области (СУБД не зависимые схемы)
- Характеристики одной или нескольких СУБД
- Вычислительные средства, ограничение на конфигурацию (что такое конфигурация?) и программное обеспечение.
- Количественная оценка эксплуатационных характеристик (оценка пользователей, или то, что они ему заказали? некоторые свойства, характерные для данного ПО), спецификация требований целостности, восстанавливаемости, безопасности, ограничение на время отклика (т.е. как быстро БД реагирует на запросы).
Теперь мы можем строить ДЛ модель. - Дополнительные требования:
- Скорость и частота выполнения приложений
- Требования к непротиворечивости
- Требования к прикладным программам
- Определение локальных информационных структур (это как?)
- Формирование СУБД-ориентированной схемы
- Оценка характеристик полученных СУБД-схем
- Усовершенствование схемы с целью повышения ее эффективности
- Создание таблицы с помощью SQL запроса. Для создания таблицы используется выражение create table <имя таблицы> (<имя поля 1> <тип поля 1>, <имя поля 2> <тип поля 2>, … );
- Добавление записи insert into <имя таблицы> (<поле 1>, <поле 2>, … ) values ((<данные 1-ой строки 1>, <данные 1-ой строки 2>, … ), (<данные 2-ой строки 1>, <данные 2-ой строки 2>, … ), …);
- Удаление записей из таблицы delete from <имя таблицы> where <имя_поля>=<условие>; Например, нужно удалить данные из таблицы, где специализация технолог, укажем, что специализация = технолог.
- Выбор данных select <имя поля 1>, <имя поля 2>, …, <имя поля n> from <имя таблицы> where <наименование поля>=<условие>; /*Если нужно выбрать все поля, то пишем вместо <имя поля 1>, <имя поля 2>, …, <имя поля n> - * */
- Редактирование записи update <имя таблицы> set <имя поля>=<значение> where <имя поля>=<условию>; /*Where указывается, когда нам нужно конкретизировать, какие данные мы будем изменять*/ Например: update <имя таблицы> set <имя>=”Василий” where <имя>=”Иван”;
- Архитектура с файловым сервером. В этом типе архитектуры функционируют два компонента:
- Файл-сервер
- Рабочая станция (иначе – клиент)
- Терминальная архитектура
- Центральная машина
- Терминал
- Клиент-сервер.
Два основных компонента (два независимых процесса): - Клиент
- Сервер
- http – это протокол, используемый для передачи web страниц в сети интернет
- https – в данном протоколе присутствует шифрование данных (s – security (защита))
- html – язык формирования документов, используемых для создания большинства web страниц (так называемый язык гипертекстовой разметки).
- url – адрес (строка из букв и цифр, обозначающая расположение или адрес некоторого ресурса в сети, а также способ доступа к нему)
- Статические – представляют из себя документ, которых хранится в отдельном файле, информацию в этом документе меняет разработчик и выкладывает на сервер (каждый раз, когда нужно обновить инфу – мы обновляем ее на локалке и выкладываем на сервер)
- Динамические – хранятся на сервере базы данных (содержимое динамической веб страницы связано с базой данных). Разметка, внешний вид страницы определены довольно четко. Динамические страницы хороши тем, что их может менять пользователь (зайдя на сервер)
- контроль данных на серверной стороне
- доступ к БД.
- Контроль данных
- Доступ к БД
- Поддержка высокой скорости получения данных из хранилища
- Поддержка внутренней непротиворечивости данных
- Возможность получения и сравнения срезов данных
- Наличие удобных утилит просмотра данных в хранилище
- Полнота и достоверность хранимых данных
- Поддержка качественного процесса пополнения данных
- Многомерные представления данных
- Прозрачность
- Доступность
- Неизменная производительность в подготовке отчетов (всегда быстро
- Поддержка архитектуры клиент-сервер
- Универсальность измерений
- MOLAP (multimation) исходные и агрегатные данные хранятся в многомерной базе данных. Это позволяет манипулировать данными, как многомерным массивом, отсюда скорость вычисления агрегатных данных одинакова для любого вычисления.
- ROLAP – (r – relation) исходные данные остаются в той же самой реляционной базе, а агрегатные данные помещаются в специально созданные для хранения служебные таблицы в той же базе данных.
- HOLAP – (h – гибрид) исходные данные остаются в той же реляционной базе данных, а агрегатные данные хранятся в многомерной базе данных.
- Многомерные
- Реляционные
- Управляемая среда запросов
- Используемые структуры данных обладают ограниченными способностями поддержки нескольких предметных областей и осуществления доступа к подробным сведениям. В некоторых программах эта проблема разрешается путем использования механизмов, которые позволяют MOLAP инструментам осуществлять доступ к подробным сведениям, содержащимся в реляционной СУБД.
- Просмотр и анализ данных ограничен тем, что структура данных был спроектирована в соответствии с заранее определенными требованиями, поэтому, для обеспечения поддержки новых требований может потребоваться реорганизация их структуры.
- Многомерное представление данных – это средства конечного пользователя, обеспечивающие многомерную визуализацию и манипулирование данными. Слой многомерного представления абстрагирован от физической структуры данных (т.е. если в физической структуре данных – это таблицы, то при разрезании куба на слои таблицы не встретятся, это будет результат среза OLAP куба)
- Многомерная обработка – средство или язык формулирования многомерных запросов
- Многомерное хранение – средство физической организации данных, обеспечивающее эффективное выполнение многомерных запросов.
Лекция 6
У нас есть два CASE-средства в зависимости от подхода (подходы бывают: функционально-модульный и объектно-ориентированный).
Тема: CASE-средства в объектно-ориентированном подходе
Объектно-ориентированный подход использует объектную декомпозицию (т.е. разделение объектов), при этом статистическая структура системы описывается в терминах объектах и связи между ними, а поведение системы описывается в терминах обмена сообщениями между объектами.
Итак, у нас есть объекты, которые разделяются на части (декомпозиция объектов), описываются связи между объектами, а также процессы (поведение системы, запросы) описываются, как сообщения.
Концептуальной основой (базовой для) объектно-ориентированного подхода является объектная модель.
Основные элементы объектной модели:
Абстрагирование – это выделение существенных характеристик некоторого объекта, которые отличают его от всех других видов объектов.
Абстрагирование концентрирует внимание на внешних особенностях объекта и позволяет отделить самые существенные особенности поведения от деталей реализации, т.е. рассматривается абстракция предметной области, и в этой абстракции предметной области мы рассматриваем наше объектно-ориентированное проектирование нашей предметной области.
(Кратко: Абстрактно рассматриваем те или иные понятия)
Инкапсуляция (ограничение доступа) – это процесс отделения друг от друга отдельных элементов объекта, определяющих его устройство и поведение. Служит для того, чтобы изолировать интерфейс объекта (то, что доступно пользователю) от внутренней реализации. Абстрагирование и инкапсуляция являются взаимно дополняющими операциями.
Абстрагирование фокусирует внимание на внешних особенностях объекта, а инкапсуляция – не позволяет объектам-пользователям различать внутреннее устройство и свойства объекта.
Модульность – это свойство системы, связанное с возможностью ее декомпозиции (разбиения) на ряд внутренне связанных между собой модулей.
Инкапсуляция и модульность создают барьеры между абстракциями (элементами системы).
Иерархия – это упорядоченная система абстракций (объектов, элементов системы), т.е. расположение их по уровням.
Основные виды иерархических структур – это структура классов и структура объектов.
Т.е. структура классов – иерархия по номенклатуре (по основным свойствам), а структура объектов – иерархия по составу.
Примерами иерархии классов является простое множественное наследование, а иерархия объектов – это агрегация (агрегирование данных – собирать воедино).
Типизация – это ограничение, накладываемое на класс объектов и препятствующее взаимозаменяемости различных классов. Типизация позволяет защищать от использования объектов одних классов от объектов других классов.
Параллелизм – это свойство объектов находиться в активном или пассивном состоянии и различать активные и пассивные объекты между собой.
Устойчивость – это свойство объекта, существовать во времени вне зависимости от процесса, породившего данный объект или в пространстве.
Основные понятия объектно-ориентированного подхода
Основными понятиями объектно-ориентированного подхода являются два понятия: объект и класс.
Объект – определяется, как осязаемая реальность (т.е. предмет или явление), имеющая четко определяемое поведение. Объект обладает состоянием, поведением и индивидуальностью. Объекты с одинаковыми свойствами и поведением образуют класс. Экземпляр класса есть объект.
Класс – это множество объектов, связанных общностью структуры и
поведением (т.е. объекты с общей структурой и поведением).
Состояние объекта характеризуется перечнем всех возможных статических свойств данного объекта и текущими значениями каждого из этих свойств.
Поведение характеризует воздействие объекта на другие объекты. Т.е. поведение объекта полностью определяется его действиями.
Индивидуальность – это свойство объекта, отличающее его от всех других объектов.
Операцией называется определенное воздействие одного объекта на другой с целью вызвать соответствующую реакцию.
Группа понятий объектно-ориентированного подхода:
Большинство методов объектно-ориентированного подхода включает:
Язык моделирования – это нотация, в основном графическая, которая используется для описания проектов.
Нотация – это совокупность графических объектов, которые используются в моделях. Нотация является синтаксисом языка моделирования.
Процесс моделирования – это описание шагов, которые необходимо выполнить при разработке проекта.
Существует универсальный язык моделирования UML (universal modulation language) – этот язык является объединением и унификацией методов (т.е. все методы собраны по классам и структурированы), разработанных тремя учеными: Буч, Рамбо и Екапсона (методы названы также). Композиция трех методов появилась в 1995 году. Создатели UML представляли его, как язык для определения, представления, проектирования и документирования программных систем.
UML содержит стандартный набор диаграмм и нотаций
Виды диаграмм:
Диаграммы вариантов пользователя – используются для моделирования бизнес процессов организации.
Диаграммы классов – для моделирования статической (не изменяемой) структуры классов и связи между ними.
Диаграммы поведения системы – отображают все процессы, проходящие в данной системе
Диаграммы взаимодействия – используются для моделирования процесса обмена сообщениями между объектами.
Диаграмма состояний – для моделирования поведения объектов системы при переходе из одного состояния в другое.
Диаграмма деятельности – для моделирования поведения системы в рамках различных вариантов использования или моделирования деятельности.
Диаграммы реализаций – их два вида:
Рассмотренные CASE-средства используются для проектирования баз данных.
Проектирование базы данных
Проектирование БД:
Цель проектирования – это определение состава и структуры базы данных, способы ее организации, выбор инструментальных средств управления данными.
Процесс проектирования включает в себя следующие этапы:
Современные CASE-средства позволяют сократить число этапов и от инфологического проектирования сразу перейти к физическому проектированию, т.е. убрать момент датологического проектирования.
Инфологический проект создается над СУБД, т.е. мы еще не привязываемся к какой-то конкретной СУБД.
Этап инфологического проектирования характеризуется созданием инфологической модели. Предполагает выделение объектов предметной области, подлежащих описанию и установлению логических связей между этими объектами. Оканчивается этот этап описанием модели предметной области в виде некоторой структуры (набора) данных. Эта структура данных соответствует объектам предметной области и связям между ними. Инфологическую модель иногда называют концептуальной моделью.
Этап датологического проектирования – предназначен для создания на основе инфологической модели логической модели будущей базы данных в среде конкретной СУБД. Для реляционных (табличных) СУБД датологическое проектирование заканчивается созданием реляционной модели базы данных, включающей полный список отношений (отношения – аналог, таблица, т.е. список таблиц), их атрибутов (перечнем столбцов) с указанием ключей (какой из столбцов будет ключевым).
Этап физического проектирования – предназначен для создания физической модели базы данных. Состоит из описания всех типов файлов базы данных. Заканчивается генерацией базы данных для выбранной СУБД.
Опытная эксплуатация – этот этап предназначен для проверки работоспособности базы данных, ее эффективности. Проводится на технике заказчика с его непосредственным участием. Срок опытной эксплуатации зависит от спецификации проекта.
Поговорим подробнее об инфологическом проектировании.
Инфологическое проектирование
Инфологическое проектирование состоит из следующих этапов:
Во время аттестации будет предложен тест в электронном виде. Там пригодятся и теоретические и практические знания.
Администратор в e-learning – Маняхина Валентина Геннадьевна.
Лекция 7
Тема: Нормализация
Нормализация - метод создания набора отношений с заданными свойствами на основании требований к данным, предъявляемым к данной организации.
Процесс нормализации впервые был предложен Коддом в 1972.
Нормализация представляет собой последовательность тестов (проверок), через которые пропускается отношение с целью проверки определённых условий.
Эти требования (тесты) называются нормальными формами.
Сначала были предложены 3 нормальные формы, затем в 1974г. Кодд и Бойс предложил ужесточить третью форму, и получились 3 формы + нормальная форма Бойса Кодда + 4 н.ф.+5н.ф.
Виды нормальные форм:
НФ – нормальная форма
НомерСотр |
Фамилия |
Адрес |
НомерОтд |
АдресОтд |
Телефон |
1. |
Иванов |
Москва |
В1 |
ул. Покровка |
1232344 |
2. |
Петров |
Дубна |
В2 |
ул. Лубянка |
3746482 |
3. |
Сидоров |
Москва |
В1 |
ул. Покровка |
3837272 |
Избыточность данных может привести к следующим проблемам:
Функциональная зависимость
Функциональная зависимость - атрибут (столбец) В функционально зависим о атрибута А если каждое значение А связано только с одним значением из В.
Обозначение функциональной зависимости: ![]()
Другими словами:
Если мы знаем значение А, то найдём только одно значение с атрибутом В.
Например:
Номер сотрудника – адрес,
Номер сотрудника – телефон Номера Отдела,
Номер отдела – фамилия не является функциональной зависимостью (т.к. для номера отдела B1 можно найти две фамилии – Иванов и Сидоров).
Ключевые поля
Потенциальный ключ это атрибут или группа атрибутов, от которого функционально зависимы все остальные атрибуты (однозначно определяет строку в таблице).
Потенциальных ключей может быть несколько, один из них первичный (главный).
Ненормализованная форма – таблица, содержащая одну или несколько повторяющихся групп данных (которая содержит повторяющиеся данные, я правильно понял?).
Первая нормальная форма
Первая нормальная форма - отношение или таблица, в которой на пересечении каждой строки и каждого столбца содержится одно значение (чем она отличается от ненормализованной формы?).
Номер клиента |
Фамилия |
Номер объекта |
Адрес |
Начало |
Конец |
Цена |
Номер владельца |
Владелец |
К1 |
Иванов |
Кв.4 |
|
1.07.12 |
31.08.12 |
50000 |
С5 |
Серов |
К1 |
Иванов |
Кв.14 |
|
1.10.12 |
5.10.12 |
10000 |
В4 |
Ветров |
К2 |
Петров |
Кв.4 |
|
1.09.12 |
1.10.12 |
25000 |
С5 |
Серов |
Для исключения повторяющихся групп используется два подхода:
Потенциальные ключи (примеры): «номер клиента + начало»; «номер клиента + конец»; «номер объекта + начало»; «номер объекта + конец» /*Почему они являются потенциальными ключами? Ведь они неоднозначно определяют запись в таблице (например, номер объекта + конец могут определять несколько фамилий, если два разных человека сняли одну и ту же квартиру в один день)*/
Первичный ключ: «номер клиента + начало»
Полная функциональная зависимость:
Атрибут «Б» полностью функционально зависим от составного
(что значит составного? имеется ввиду ключа?)
атрибута «А», если он зависит от «А» и не зависит от любого подмножества «А»
(какое подмножество может быть у столбца таблицы? или здесь имеется ввиду, что «А» - составной ключ, а «Б» функционально зависим от ключа «А» и не зависим от любого атрибута ключа «А»).
/*Частичной зависимостью (частичной функциональной зависимостью) называется зависимость не ключевого атрибута (столбца, который не является ключом) от части составного ключа.*/
Пример:
фамилия частично зависима от первичного ключа (т.е. от отношения «номер клиента + начало», фамилия – не ключевой атрибут, зависима от атрибута “номер клиента”, который является частью составного ключа).
Номер объекта полностью функционально зависим от первичного ключа.
/*т.к. в первичном ключе «номер клиента + начало» атрибут «номер клиента» не является уникальным. Аналогично, атрибут «начало» тоже не является уникальным*/
Вторая нормальная форма
Вторая нормальная форма – это отношение (таблица), которое находится в первой нормальной форме и каждый атрибут, не входящий в состав первичного ключа, полностью функционально зависим от первичного ключа, т.е. нам надо найти все частичные зависимости и выделить их в отдельные таблицы.
Функциональная зависимость 1 (ФЗ 1): Номер клиента + Начало ![]() Номер объекта + Адрес + Конец + Номер владельца + Владелец + Цена (полная функциональная зависимость)
Номер объекта + Адрес + Конец + Номер владельца + Владелец + Цена (полная функциональная зависимость)
ФЗ 2: Номер Клиента, Конец ![]() Номер Объекта, Адрес, Начало, Номер Владельца, Владелец, Цена
Номер Объекта, Адрес, Начало, Номер Владельца, Владелец, Цена
Ф.З. 3: номер объекта, начало ![]() (какие тут атрибуты?)
(какие тут атрибуты?)
Ф.З.4: номер объекта, конец ![]() (какие тут атрибуты?)
(какие тут атрибуты?)
Ф.З. 5: номер клиента ![]() фамилия (частичная зависимость)
фамилия (частичная зависимость)
Что определяют эти таблицы, зачем мы их создали?
Таблица 1: Клиенты (номер клиента, Фамилия) (т.к. между ними частичная зависимость)
Таблица 2: Аренда (номер клиента, Начало, конец, номер объекта, адрес владельца, владелец, цена)
(мы разбили одну таблицу на две, но с полной функциональной зависимостью?)
З НФ (третья нормальная форма)
Транзитивная зависимость
A![]() B, B
B, B![]() C, тогда A
C, тогда A![]() C.
C.
3 нормальная форма - это отношение, которое находится во второй нормальной форме и не имеет транзитивных зависимостей от первичного ключа.
Пример:
Номер клиента, начало ![]() Номер объекта
Номер объекта
Номер объекта ![]() Адрес, цена, номер владельца, владелец.
Адрес, цена, номер владельца, владелец.
Номер владельца ![]() владелец
владелец
Поэтому по транзитивности мы можем получить:
Номер клиента, начало ![]() владелец.
владелец.
или
Номер клиента, начало ![]() Адрес
Адрес
Уберем все транзитивные зависимости из таблицы Аренда (в таблице Клиенты нет транзитивных зависимостей), получим следующие таблицы:
Из ![]() получаем:
получаем:
![]() : Аренда (номер клиента, начало, конец, номер объекта)
: Аренда (номер клиента, начало, конец, номер объекта)
![]() : Объекты (номер объекта, адрес, номер владельца, цена)
: Объекты (номер объекта, адрес, номер владельца, цена)
![]() : Владельцы (номер владельца, фамилия)
: Владельцы (номер владельца, фамилия)
И не забываем про ![]() : Клиенты:
: Клиенты:
![]() : Клиенты (номер клиента, фамилия)
: Клиенты (номер клиента, фамилия)
Получилась третья нормальная форма.
НФБК (нормальная форма Бойса Кодда)
Отношение (таблица) находится в нормальной форме Бойса Кодда тогда и только тогда, когда каждый его детерминант является его потенциальным ключом. (А![]() В А - детерминант).
В А - детерминант).
Нарушение требования происходит, когда имеется более 2-х составных потенциальных ключей, и они перекрываются (что значит перекрываются?).
Можно ли привести пример оптимизации таблиц выше?
Лекция 8
Процесс нормализации входит в инфологическое проектирование.
/*Повторение*/
1) Этап создания инфологической модели, выделение объектов предметной области и связи между ними.
2) Этап создания логической модели
3) Этап создания физической модели
4) Этап опытной эксплуатации
Инфологическое проектирование:
/*----------------------------------------------------*/
1 шаг выделение сущностей
Сущность представляет собой элемент множества реальных или абстрактных объектов в некоторой предметной области, обладающих общими характерными свойствами.
Соглашения для сущности:
шаг 2 выделение атрибутов
Атрибут – это некоторое свойство сущности.
Каждый атрибут имеет свое уникальное имя
Значения всех атрибутов в конкретном экземпляре сущности не должны повторяться
3-й шаг - Выделение и установление связей между сущностями и атрибутами
Существуют четыре типа связи на одном уровне иерархии.
4-й шаг – нормализация модели.
Нормализация отношений – это обратимый пошаговый процесс декомпозиции исходных отношений на более простые, при которых устраняются нежелательные зависимости (разделение на разные таблицы).
Чем серьезнее накладываются условия на атрибуты сущности, тем серьезнее нормальная форма.
Последняя нормальная форма – это форма Бойса Кодда.
5-я и 6-я НФ практически не употребляются.
5-й шаг. Минимизация числа сущностей.
Процесс нормализации – это разбиение таблиц. Это чревато появлением новых таблиц. Поэтому некоторые появившиеся таблицы могут дублироваться. Их либо убирают в одну или еще чего-то. Это и есть минимизация сущностей.
/*Будет тест на семинарском занятии по теоретическому материалу*/
Правила минимизации сущностей:
Этап датологического проектирования.
Этот этап характерен СУБД-ориентированной схемы базы данных.
Прежде, чем перейти к д.л. проектированию, разраб должен иметь следующее:
В результате ДЛ проектирования мы получаем
1) СУБД-ориентированную схему с учетом специфики структуры и архитектуры СУБД.
2) Пакет прикладных программ и руководство по их применению
3) Руководство для группы сопровождения базы данных (администрация, обслуживающий персонал, методисты).
Шаги ДЛ проектирования после выбора инструментального средства:
Т.о., когда мы задумываем проектировать БД, то все это нужно будет создать.
Нужно сформулировать свою предметную область.
Дальше мы начинаем процесс проектирования
1) Инфологическое проектирование. У нас появится модель, которая появится с помощью CASE-средства. В рамках одного файла мы создаем несколько листов, на этих листах помещаем схемы. Существет ICOM модель, состоящая из блоков (7 лаба – заполнение зачетной книжки, все детализируем и детализируем).
Появляются сущности, атрибуты, связи между сущностями.
Потом переходим к реализации СУБД, мы создаем запросы, связи, таблицы. Мы должны повторять логику схемы данных, которая была создана в процессе инфологического проектирования. Т.е. схема в ACCESS должна идти за CASE средством. Одна из серьезных ошибок – схема в CASE средстве и в реализации не совпадают.
Язык структурированных запросов SQL
SQL – язык структурированных запросов.
Основным достоинством этого языка состоит в том, что этот язык является унифицированным, т.е. существует стандартный набор определенных команд, которые могут использоваться в различных СУБД.
SQL может использоваться, как интерактивный, так и встроенный язык.
Интерактивный, это когда использование происходит для выполнения запросов.
В качестве встроенного языка, SQL используется для построения прикладных программ.
В SQL существуют предложения определения даты, запросы на выбор данных, предложения модификации данных, арифметические вычисления.
В SQL используются следующие основные типы данных:
1) integer – вмещает до 10 значащих цифр
2) smallint – вмещает в себя до 5 значащих цифр
3) float – вещественное число с 15-ю значащими цифрами
4) char(n) – символьная строка, длины n, где n лежит в промежутке [0; 256]
5) date – дата (месяц, день, год)
time – время (часы, минуты, секунды)
money – денежный тип (в денежной единице)
Основные функции языка SQL
Лекция 9
Несколько слов о 7-ой и 8-ой лабораторных работ.
При выполнении лабы 7. Схему проекта буду отрисовывать в этой программе. В этой программе нужно было использовать иерархическую структуру.
Установление надписей А0, и т.д. происходит при выделении формы и нажатии на кнопку с фигурками. Короче, также, как я и делал.
К потомку прийдет только та информация, которая была у предка. Остальную информацию нужно будет дорисовать (контроль или ресы).
8-я лаба
В 8-ой лабе нужно создать схему, которая отражает сущность-связь.
Надпись (FK) – внешний ключ. Надпись код предмета (FK) появится сама, когда начну строить диаграмму сущность-связь (когда устанавливаю связи).
Проектная работа (свой собственный проект)
Все требования к проекту на сайте существуют в качестве 9-ой лабораторной работы.
Выбрать предметную область. Предметная область – пример, я хочу делать базу данных о книгах, библиотека – предметная область. или видеотека – предметная область.
Определить функции и потоки данных данной предметной области – выделяем сущности в данной предметной области и строим взаимосвязи между этими сущностями. Построить SADT диаграмму.
Пример: библиотека вмещала сущности авторы и книги. В авторах – код автора, перечень книг и т.д. (атрибуты). Потоки данных – построить функциональную модель (7 лаба). Т.е. после того, как я продумал предметную область и из чего будут состоять сущности. Нужно выделить функции предметной области. Пример: оформление зачетной книжки – основное назначение. Второе – детализируем основную функцию на (пример, оформление зачетного листа и т.д.) детализация функций и процессов. Если в качестве основной функции идет функция работа в библиотеке, то мы проводим детализацию этой функции (оформление читательских билетов, оформление кодификатора книг) и т.д. Я выбираю несколько функций и детализирую. Оформление листов сессии делится на: оформление листа зачетов (стрелочки от зачетов к контролю допуска сессии).
Считаем, что это д.з.
Выделить предметную область и построить модели.
4. Иденцификация сущностей. Когда мы определили потоки данных, нужно определить атрибуты каждой сущности и установить связи (ERD – диаграмма, сущность-связь, лаба 8)
5. Нормализовать модель.
8. Минимизировать число полученных сущностей. Если поля совпадают ключевые поля, то нужно эти таблицы минимизировать. Второе, если поля одной таблицы полностью входят в другую, то наименьшую сущность нужно будет уничтожить.
Построить концептуальную схему выбранной предметной области – дублирует схему данных в моей СУБД. ??? (ERD диаграмма) Тут уже описываются сущности и связи между ними.
Через неделю будут просить показать SADT модели (функциональные модели) и ERD – модели.
ERD диаграмма является нормализованной SADT диаграммой.
Защита проекта Надежде Юрьевне.
Лабораторные работы 10 и 11 состоятся. MySQL установлен.
Примеры SQL-запросов:
Ряд примеров заполнения таблиц.
Создадим две таблицы:
На языке SQL необходимо создать таблицу, вмещающую в себя следующие данные:
Код студента (PK) |
Фамилия |
Имя |
Отчество |
Группа |
Курс |
Факультет |
create table студенты (Код_студента integer, фамилия char(25), имя char(25), отчество char(25), группа char(3) /*Например 103 – 3-я группа 1-го курса*/, курс smallinteger, факультет char(50));
Создадим таблицу предметы:
Код студента (FK) |
Название предмета |
Оценка |
create table предметы (Код студента integer, Название предмета char(150) /*можно указать тип MEMO*/, оценка smallint);
Что чем будет?
Для первой таблицы возвращаясь к диаграмме сущность-связь (ERD) код студента будет Primary Key, код студента в таблице предметы будет FK (foreign key)
В 8-ой лабе не нужно было бы делать код студента во второй таблице.
Для того, чтобы заполнить таблицу данными, заюзаем команду insert into:
insert into студенты (код_студента, фамилия, имя, отчество, группа, курс, факультет) values (
(1, Иванов, Василий, Петрович, 3, 4, математический),
(2, Петров, Иван,,3, 4, математический),
);
Первую таблицу мы заполнили. Заполним вторую таблицу.
insert into предметы (код_студента, название предмета, оценка) values ((1, Алгебра, 5), (1, Геометрия, 4), (1, Русский язык, 3), (2, Алгебра, 3));
Покажем пример на удаление данных:
delete from Предметы where оценка=2; /*Этим запросом мы удалили бы всех двоечников из таблицы Предметы*/.
Выборка данных:
Выберем из нашей таблицы отличников
select /*поля, где растет большая конопля*/ код_студента, предмет, оценка from предметы where оценка=5;
Запрос на выбор всех записей – select * from студенты; - запрос на выборку всех данных из таблицы студенты.
Редактирование записей:
update студенты set имя=”Петр” where код_студента=2;
Основные моменты мы указали. Начнем следующую тему:
Реализация Клиент-Серверных приложений. Когда есть сервер, на сервере развернута программа, клиентская машина не хранит информацию, она вся на сервере.
Тема: СУБД в архитектуре клиент-сервер
Перспективы развития систем управления базами данных (СУБД).
Три типа архитектуры ИС существуют в настоящий момент:
Эти компоненты работают на любых компьютерах, соединенных в локальную сеть. Файл-сервер по сети воспринимает запросы от рабочей станции. Запросы к файлу-серверу формируются на уровне доступа к файлам.
Все функции по обработке данных и по формированию пользовательского интерфейса выполняются на рабочей станции. Типичным примером такой архитектуры является:
Прикладная система, реализованная на СУБД Fox Pro.
Вся обработка данных ведется на центральной машине, пользовательский интерфейс формируется на центральной машине. Терминалы служат только для визуализации информации и ввода с клавиатуры.
Терминальная схема может быть реализована с помощью любых аппаратных конфигураций. Пример: Windows 7 можно будет загрузить с центральной машины, а колымаги (старые компы) будут работать, как терминалы.
Сервер в данном случае называется сервером базы данных и работает на том компьютере, на котором хранятся данные. Клиент работает на ПК пользователя. Связи между ними осуществляются по сети. Отличие от файл-серверного приложения в том, что клиент-серверное приложение может обрабатывать запросы более высокого уровня.
Клиент и сервер делят между собой функции следующим образом:
Клиент – формирует интерфейс пользователя, создает удобную среду для представления и ввода данных, формирует запросы к серверу на чтение и изменение данных.
Сервер получает по сети запросы от клиента, выполняет их, отслеживает сохранение целостности и согласованности данных и выдает клиенту результат запроса.
Запросы к серверу обычно формируются на языке SQL.
Часто можно увидеть название соответствующих программных средств SQL сервер. Поэтому программный продукт Microsoft SQL server тоже самое /*см. лекцию на диктофоне*/
Перспективы развития СУБД
Классические реляционные СУБД несмотря на все достоинства являются ограниченными.
Если мы рассмотрим пост реляционные системы, то мы можем выделить несколько направлений.
1 направление:
Postgres (постгрес или постгрэс)
Основной смысл этого направления состоит в том, что он имеет такие же гибкие и мощные средства структуризации данных, которые были присущи иерархическим и сетевым системам баз данных. Данное направление основано на системах баз данных в которых не поддерживается первая нормальная форма (не можем выделить отношения между объектами, т.е. поля).
В ненормализованных моделях данных допускается сохранение данных в качестве элементов кортежа, в этом же направлении реализованы поддержка так называемой темпаральной модели хранения и доступа к данным.
Полностью пересмотрен механизм изменения, восстановления баз данных.
Основной тезис темпаральных систем:
(темпаральный от слова temp - время).
Для того, чтобы любой объект данных, созданный в момент времени t1 был уничтожен в момент времени t2. В базе данных сохраняются доступы пользователей во временном интервале [t1; t2]
2-е направление:
Exodus/Genesis
Основная характеристика создания собственно не системы, а генератора систем наиболее полно соответствующего потребностям приложений.
Решение этого вопроса достигается путем создания набора модулей со стандартизированными интерфейсами.
Основание: Принцип модульности и точное соблюдение установленного интерфейса.
3-е направление:
Starburst
Основная характеристика: достижение расширяемости системы, ее приспосабливаемости к нуждам конкретных приложений путем использования стандартного механизма управления правилами. Фактически, это интерпретатор наборов правил и модулей действий.
4-е направление:
Web-СУБД
Сущестуют два понятия: интернет и интранет.
Интернет – всемирный набор взаимодействющих компьютерных систем.
Интранет – корпоративная сеть, действующая в организации, но использует все технологии Web приложений.
Экзернет – локальная сеть.
Лекция 10
При сдаче работ на CASE средства быть готовым ответить на контрольные вопросы и ответить, как из функциональной схемы перейти в концептуальную схему.
Продолжаем рассказ о перспективах развития СУБД.
В прошлый раз остановились на направлении Веб СУБД
Существуют два понятия:
Интранет – сеть, которая действ. в одной организации и обладает свойствами интернет
Интернет – всемирный набор взаимодейств. компов.
Свойства интернет:
E-mail
FTP протокол
Телеконференции
Средства интерактивного общения
www технологии – это гипермедиа система, позволяющая простые средства типа “укажи и щелкни” для набора информации использовать в сети интернет (с помощью механизма гиперссылок).
Основные компоненты среды www:
WEB страницы делятся на два типа:
Говоря о динамических веб страницах, мы можем сказать, что существует двухуровневая и трехуровневая архитектура клиент-сервер:
Двухуровневая – на первом уровне клиент ПК, функции, которые есть у клиента – это интерфейс пользователя и основная логика обработки данных. На втором уровне находится сервер. Функции:
Говоря о трехуровневой архитектуре, мы можем сказать, что:
На первом уровне клиент с функцией интерфейс пользователя
На втором уровне сервер приложений с функциями основная логика приложений и логика обработки данных.
На третьем уровне находится сервер базы данных.
Функции сервера:
В данной архитектуре логику обработки данных берут сервер-приложения.
Далее поговорим об OLAP
Тема OLAP
OLAP – это оперативная аналитическая обработка, которая позволяет производить динамический синтез, анализ, консолидацию (соединение в одно) больших объемов многомерных данных.
OLAP представляет собой технологию, отличную от двумерных моделей. Позволяет анализировать трехмерные и четырехмерные таблицы. Т.е. анализ происходит по многомерному пространству. Чаще всего инфа представляется в виде куба и анализируется.
OLAP – это аббревиатура от словосочетания online analytical processing (эти три слова полностью раскрывают все технологии OLAP), т.е. в режиме реального времени происходит анализ данных.
OLAP не является отдельным продуктом, это совокупность концепций, принципов, требований, лежащих в основе программных продуктов и облегчающих аналитикам доступ к данным.
Оперативные сведения собираются из различных источников, очищаются (т.е. отбрасывается все ненужное для анализа), интегрируются и складываются в дальнейшем в реляционное хранилище, после этого эти сведения доступны для анализа с помощью различных средств построения отчета.
Затем данные подготавливаются для OLAP анализа.
Они могут быть загружены в специальную базу данных OLAP или оставлены в реляционном хранилище.
Важнейшим элементом являются метаданные.
Метаданные – это информация о структуре, размещении и трансформации данных.
Благодаря этому обеспечивается эффективное взаимодействие различных компонентов хранилища.
Что такое хранилище данных?
Принять любое управленческое решение невозможно не обладая некоторой информацией, для этого необходимо создать хранилище данных, отсеивание не нужной информации и произведения анализа данных.
Автор хранилища концепции данных Ральф Кембал описывал хранилище данных, как:
место, где люди могут получить доступ к своим данным.
Он также сформулировал основные требования к хранилищам данных как то:
Для реализации хранилищ данных используются, как правило, несколько программных продуктов, одно из которых является средством хранения данных, а второй – средство извлечения данных, может присутствовать и третий (для пополнения данных).
Пример:
Портал, его обслуживает СУБД (например, MySQL), отображение представляет оболочка (например, Мудл – на e-learning), визуализирует работу базы данных. Если мы возьмем форум, то это тоже будет оболочка, которая позволяет вносить изменения и дополнения к базе данных.
Типичное хранилище базы данных отличается от обычной реляционной базы данных.
Во-первых, обычные БД предназначены для того, чтобы помочь пользователям выполнить всю повседневную работу, тогда, как хранилища данных предназначены для принятия решений, например, продажа товара, выписка счета производится с помощью базы данных, которая, естественно, позволяет работать с различными рода транзакциями (проводками).
А анализ продаж за последние несколько лет, который позволяет спланировать работу с поставщиками осуществляется за счет хранилища данных.
/*Экономики проходят 1С)))*/
Во-вторых, Обычные базы данных подвержены постоянным изменениям в процессе работы пользователей.
Хранилище данных относительно стабильно, данные в нем обновляются согласно расписанию.
Например: еженедельно, ежедневно и т.д.
В идеале процесс пополнения представляет собой добавления новых данных за определенный период времени без изменения прежней информации.
В-третьих, обычные базы данных чаще всего являются источником данных, попадающих в хранилище, кроме того, хранилище может пополниться за счет внешних источников, например, статистических.
Что же представляет из себя типичная структура хранилища данных?
Типичная структура хранилища данных существенно отличается от структуры реляционной БД, как правило, эта архитектура не представлена ни в какой нормальной форме, т.е. она денормализована и, поэтому, может допускать избыточность данных.
Говоря о многомерном анализе (OLAP анализе), мы скажем, что он может быть произведен с помощью различных средств, которые можно разделить условно на клиентские и серверные OLAP средства.
Клиентские OLAP средства представляют собой приложения, осуществляющие вычисления агрегатных данных (данные, для вычисления которых требуется обработка массива данных, т.е. суммирование, нахождение максимальной, минимальной величины, т.е. происходит агрегирование данных, например, запрос по сумме стран, сумма и количество стран (группировка – групповые операции аналог агрегирования данных)) их отображения, при этом сами агрегатные данные содержатся внутри адресного пространства (внутри куба) такого OLAP средства.
Если исходные данные содержатся в настольной (локальной) СУБД, вычисление агрегатных данных производится самим OLAP средством.
Если источник данных – серверная СУБД, то многие из клиентских OLAP средств посылают на сервер SQL запросы, содержащие оператор GROUP BY и в результате получают данные, вычисленные на сервере. Как правило, OLAP функциональность реализована в средствах статистической обработки информации. Она есть в EXCEL, есть программный продукт (SPCC с одноименным программным продуктом для обработки статистики, т.е. если нужно провести опрос, а потом проанализировать данные, то их нужно статистически обработать в EXCEL или с помощью SPCC (или SPSS ?)).
С помощью EXCEL можно хранить данные в виде OLAP куба (на одной грани одни данные, в другой грани другие, на третьей грани еще какие-то)
Правила OLAP систем:
Лекция 11
Тема: Продолжение рассказа о многомерных кубах данных
Говоря о способах хранения многомерных данных, мы можем выделить 3 способа:
В 1995 году на основе требований к многомерным базам данных, которые сформулировал Эдгар Кодд (в 93-м описал концепцию). На основе этих требований был сформирован тест FASMI (fast analysis of shared multidementional information – быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям многомерного анализа:
1) Fast (быстрота) – оно говорит о предоставлении пользователю результатов за приемлемое время (обычно (как правило) 5 секунд).
2) Анализ – возможность осуществления любого логического и статистического анализа, характерного для данного приложения и его сохранения в доступном для конечного пользователя виде.
3) Разделяемая – многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизированного доступа. Именно по этому пути идут большинство СУБД.
4) Многомерный – многомерное концептуальное представление данных, включает полную поддержку для иерархий и множественных иерархий.
5) Информация – приложение должно иметь возможность обращаться к любой нужной информации не зависимо от ее объема и места хранения. Храниться информация может в различных видах, в том числе в кубах.
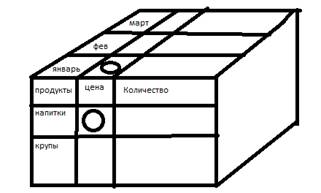
В верхней плоскости мы получим цену за напитки в январе (на пересечении трех …)
Правила для OLAP систем:
Динамическое управление
… (см. прошлую лекцию) и
Многопользовательская поддержка
Поддержка интуитивно понятного манипулирования данными
Инструмент для работы с OLAP системами – это язык ROLAP.
От пользователя поступает запрос, который поступает в приложения, где на языке ROLAP перерабатывается запрос и в виде SQL летит на сервер.
Управляемая среда запросов (MQE) – это относительно новая разработка. Эти инструменты предоставляют ограниченные функции анализа либо непосредственно реляционной СУБД, либо с помощью промежуточного MOLAP сервера.
Категории MOLAP инструментов:
При разработке MOLAP инструментов следует учитывать следующие особенности:
Когда мы рассматриваем кубы OLAP, то они подвергаются разрезанию и данные, которые получаются на срезе – это агрегированные данные (пересечения), которые содержат в себе (если мы делаем разрезание по верхней грани, то данные идут по цене для каждого месяца в отдельности, по количеству за каждый месяц в отдельности).
Мы можем делать двумерные срезы по разным измерениям:
Мы можем срезать отдельно по январю, отдельно по январю, отдельно по марту, тогда срез будет сделан по трем измерениям (для каждого среза мы получим двумерную таблицу)
Значения, которые откладываются вдоль измерений называются членами или метками (members англ.).
Метки используются как для разрезания куба, так и для ограничения (фильтрации) выбираемых данных.
??? (так что такое метки?)Значения меток отображаются в двумерном представлении куба, как заголовки строк и столбцов.
Метки могут определяться в иерархии, состоящие из одного или нескольких уровней.
Например:
Мир, страна, регион, город, магазин
В соответствии с уровнями выдвигаются агрегатные значения, например, объем продаж для конкретной страны или для региона.
Иерархии могут быть сбалансированными и несбалансированными.
Примером несбалансированной иерархии является начальник-подчиненный.
Сбалансированный – иерархия дата-время.
Есть иерархии, которые занимают промежуточное положение между сбалансированными и несбалансированными. Обычно они содержат такие члены, логические родители которых находятся не на вышестоящем уровне, а между уровнями.
Где на кубе агрегированные данные? (кружочек, который внутри) (просто на кубе два круга, какой из них нужен, что означает второй круг? второй кружочек означает выбор столбца) Что такое метки? Чем различаются метки и значения меток?
Архитектура OLAP приложения.
Многомерность в OLAP приложениях может быть разделена на три уровня:
Первые два уровня в обязательном порядке присутствуют во всех OLAP системах.
Третий уровень является широко распространенным, но не является обязательным.
Например:
OLAP клиентами могут являться электронные таблицы в EXCEL (если я в экселе рассматриваю различные таблицы, то я могу совместить их в OLAP куб).
Поддеривает многомерную OLAP систему сервер Oracle.
У фирмы Microsoft тоже существует сервер – это Mircoroft OLAP server.
Слой многомерной обработки обычно бывает встроен в OLAP клиент или в OLAP сервер, так же он может быть выделен в чистом виде в качестве компонента.
Организационные моменты:
На следующей неделе этой лекции нет.
25-го лекции не будет. Гуляем!!!
Эта неделя, конец следующей недели, нужно подготовиться к тому, что в е-лернинге будет тест. L.
Меньше 50%, то хреново (неуд).
Тест будет во всех группах? Что будет в тесте (какие темы)?
Итоговый проект вмещает в себя описание, БД и рассказ
(тест 29-го, все вопросы)
Практика MySQL
Работа № 10. Создание запросов на языке SQL (СУБД MySQL)
Задание № 1. Подсоединение к серверу и отсоединение от него
При подключении к серверу с помощью mysql обычно нужно ввести имя
пользователя MySQL и, в большинстве случаев, пароль. Если сервер запущен не на
том компьютере, с которого вы вошли в систему, необходимо также указать имя
хоста. Параметры соединения (соответствующее имя хоста, пользователя и пароль)
вы сможете узнать у администратора. Получив соответствующие параметры,
подсоединиться к серверу можно следующим образом:
shell> mysql -h host -u user -p
Enter password: ********
Символы ******** обозначают ваш пароль; введите его, когда mysql выведет на
экран запрос Enter password:.
Если все сработает, на экране должна появиться следующая информация и метка
командной строки mysql>:
shell> mysql -h host -u user -p
Enter password: ********
mysql>
Метка обозначает, что программа mysql готова к вводу команд.
После установки соединения можно в любой момент отключиться от сервера,
набрав в командной строке mysql> команду QUIT:
mysql> QUIT
Bye
Отсоединиться от сервера можно и при помощи сочетания клавиш Control-D.
Задание № 2. Ввод простейших запросов без использования базы данных.
1. Ниже приведена простая команда, запрашивающая у сервера информацию об его
версии и текущей дате. Введите ее в командной строке mysql> и нажмите Enter:
mysql> SELECT VERSION(), CURRENT_DATE;
1
Для ввода ключевых слов можно использовать любой регистр символов. Убедитесь,
что приведенные ниже запросы абсолютно идентичны:
mysql> SELECT VERSION(), CURRENT_DATE;
mysql> select version(), current_date;
mysql> SeLeCt vErSiOn(), current_DATE;
2. Ниже демонстрируется использование mysql в качестве несложного калькулятора:
mysql> SELECT SIN(PI()/4), (4+1)*5;
Все команды, представленные выше, были относительно короткими и состояли из
одной строки. В одну строку можно поместить и несколько команд. Но каждая из
них должна заканчиваться точкой с запятой:
mysql> SELECT VERSION(); SELECT NOW();
3. В нижеследующей таблице приведены все возможные варианта вида метки
командной строки и соответствующие им состояния mysql:
Метка Значение
mysql>
Ожидание новой команды.
->
Ожидание следующей строки многострочной команды.
'>
Ожидание
следующей
строки,
сбор
строкового
выражения,
начинающегося с одиночной кавычки.
">
Ожидание
следующей
строки,
сбор
строкового
выражения,
начинающегося с двойной кавычки.
Запишите данные таблицы в тетрадь.
Обычно многострочные команды получаются случайно, когда хочешь создать
обычную команду, но забываешь поставить завершающую точку с запятой. В таком
случае mysql ожидает продолжения:
mysql> SELECT USER()
->
Метки '> и "> используются при сборе строк. В MySQL строки можно заключать как
в одинарные ('), так и в двойные (") кавычки (можно, например, написать 'hello' или
"goodbye"), кроме того, mysql позволяет вводить строковые выражения, состоящие
из нескольких строчек текста. Метка '> или "> обозначает, что вы ввели строку, открывающуюся символом кавычек (' или "), но еще не ввели завершающую
строковое выражение закрывающую кавычку.
2
Знать значение меток '> и "> необходимо, так как при вводе незавершенной строки
все последующие строки будут игнорироваться mysql, включая строку с командой
QUIT.
Задание 3. Проверка наличия баз данных на сервере, создание и выбор базы
данных
1. Проверьте наличие каких-либо баз данных на сервере в настоящее время при
помощи команды SHOW:
mysql> SHOW DATABASES;
На вашем компьютере список баз, вероятно, будет другим, но в нем все равно,
скорее всего, будут присутствовать базы mysql и test. База данных mysql просто
необходима, так как в ней она описываются пользовательские права доступа. База
test часто применяется для экспериментов.
Если база данных test существует, попробуйте обратиться к ней:
mysql> USE test
Database changed
В команде USE, как и QUIT, точка с запятой не нужна (однако данные команды
тоже можно завершать точкой с запятой). Команда USE отличается от остальных –
она должна задаваться одной строкой.
2. Если администратор при выдаче разрешения создаст для вас базу, с ней можно
сразу начинать работу. В противном случае вам придется создать ее
самостоятельно:
mysql> CREATE DATABASE menagerie;
Создавать базу нужно только однажды, но выбирать ее приходится в каждом сеансе
работы с mysql. Делать это можно с помощью команды USE, представленной выше.
Можно также выбирать базу из командной строки при запуске mysql. Для этого
достаточно лишь ввести ее имя после параметров соединения, которые нужно
вводить в любом случае. Например:
shell> mysql -h host -u user -p menagerie
Enter password: ********
3
Задание 4. Создание таблицы
1. Убедитесь при помощи команды SHOW TABLES, что в Вашей базе пока нет
таблиц: mysql> SHOW TABLES;
2. Создайте таблицу «pet», содержащую поля имя (name), владелец (owner),
вид_животного (species), пол (sex), дата_рождения (birth), дата_смерти (death). Пол
животного будем обозначать буквами "m" (мужской) и "f" (женский).
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20), species
VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
3. Проверьте наличие в базе данных таблицы pet с помощью команды SHOW
TABLES.
4. Убедитесь в правильности создания таблицы при помощи команды DESCRIBE:
mysql> DESCRIBE pet;
Использовать команду DESCRIBE можно в любое время, например, если вы
забудете имена столбцов или типы, к которым они относятся.
Задание 5. Загрузка данных в таблицу
1. Заполните таблицу следующими записями (обратите внимание: MySQL
принимает даты в формате ГГГГ-ММ-ДД), создав текстовый файл.
name
owner
species
sex
birth
death
Fluffy
Harold
cat
f
2005-02-04
Claws
Gwen
cat
m
2006-03-17
Buffy
Harold
dog
f
1999-05-13
Fang
Benny
dog
m
2000-08-27
Bowser
Diane
dog
m
2008-08-31
2005-07-29
Chirpy
Gwen
bird
f
2008-09-11
Whistler
Gwen
bird
2007-12-09
Slim
Benny
snake
m
2006-04-29
Так как первоначально таблица пуста, заполнить е? проще всего, создав
текстовый файл, содержащий по строке на каждое из животных, а затем загрузив его
содержимое в таблицу одной командой. Создайте текстовый файл с именем
«pet.txt», содержащий по одной записи в каждой строке (значения столбцов должны
быть разделены символами табуляции и даны в том порядке, который был
определен командой CREATE TABLE). Незаполненным полям (например,
4
неизвестный пол или даты смерти живых на сегодняшний день животных), можно
присвоить значение NULL. В текстовом файле это значение представляется
символами . Например, запись для птицы Whistler должна выглядеть примерно
так (между значениями должны располагаться одиночные символы табуляции):
name
owner
species
sex
birth
death
Whistler
Gwen
bird
2007-12-09
Загрузить файл «pet.txt» в таблицу можно с помощью следующей команды:
mysql> LOAD DATA LOCAL INFILE "С:.txt" INTO TABLE pet;
2. Добавьте одиночную запись в таблицу. Предположим, Диана (Diane) купила
хомячка по имени Puffball. Соответствующую запись в таблицу можно внести с
помощью команды INSERT:
mysql> INSERT INTO pet
-> VALUES ('Puffball', 'Diane', 'hamster', 'f', '2009-03-30', NULL);
Обратите внимание на то, что здесь строковые выражения и даты представлены в
виде ограниченных кавычками строк. Кроме того, в команде INSERT
отсутствующие данные можно прямо заменять на NULL (вместо как в команде
LOAD DATA).
Задание 6. Выборка всех данных из таблицы, проверка и исправление ошибок.
1. Просмотрите все данные в таблице pet:
mysql> SELECT * FROM pet;
Убедитесь, что дата рождения и смерти для собаки Bowser введены неверно.
2. Исправьте ошибку, отредактировав файл pet.txt (ввести произвольное подходящее
по смыслу значение даты рождения), очистив таблицу и снова заполнив ее:
mysql> DELETE FROM pet;
mysql> LOAD DATA LOCAL INFILE "pet.txt" INTO TABLE pet;
Убедитесь, что запись о Puffball отсутствует, введите е? снова.
3. Исправьте только ошибочно введенные данные при помощи команды UPDATE:
mysql> UPDATE pet SET birth = "1998-08-31" WHERE name = "Bowser";
5
Задание 7. Выборка определенных строк из таблицы
1. Проверьте правильность внесенных в дату рождения собаки Bowser изменений:
mysql> SELECT * FROM pet WHERE name = "Bowser";
В операции сравнения строк обычно не учитывается регистр символов, так что имя
можно записать как "bowser", "BOWSER" и т.п. Убедитесь, что результаты запросов
будут идентичными.
2. В условиях может указываться любой из столбцов, а не только name. Узнайте,
какие их животных родились после 2008 года:
mysql> SELECT * FROM pet WHERE birth >= "1998-1-1";
3. Создайте запрос, комбинируя несколько условий для выделения всех собак
женского пола (с использованием оператора AND):
mysql> SELECT * FROM pet WHERE species = "dog" AND sex = "f";
4. Создайте запрос, комбинируя несколько условий для выделения всех змей или
птиц (с использованием оператора OR):
mysql> SELECT * FROM pet WHERE species = "snake" OR species = "bird";
5. Используйте операторы AND и OR совместно для выявления всех кошек
женского пола и всех собак мужского (скобки указывают на порядок группировки
условий):
mysql> SELECT * FROM pet WHERE (species = "cat" AND sex = "m") OR (species =
"dog" AND sex = "f");
Задание 8. Выборка определённых столбцов
1. Создайте запрос, позволяющий узнать, когда родились животные:
mysql> SELECT name, birth FROM pet;
2. Получите имена владельцев животных можно с помощью следующего запроса:
mysql> SELECT owner FROM pet;
3. Сократите количество выводимых строк, воспользовавшись ключевым словом
DISTINCT (в этом случае будут выводиться только уникальные записи):
mysql> SELECT DISTINCT owner FROM pet;
6
4. Используйте выражение WHERE для комбинирования выбора строк и столбцов:
загрузите даты рождения только кошек и собак:
mysql> SELECT name, species, birth FROM pet WHERE species = "dog" OR species =
"cat";
Задание 9. Сортировка строк
1. Отсортируйте даты рождения животных с помощью команды ORDER BY:
mysql> SELECT name, birth FROM pet ORDER BY birth;
2. Для сортировки в обратном порядке к имени столбца следует добавить ключевое
слово DESC (по убыванию):
mysql> SELECT name, birth FROM pet ORDER BY birth DESC;
3. Проведите сортировку по нескольким столбцам сразу. Для того чтобы
отсортировать таблицу сначала по типу животного, потом по дате рождения и затем
расположить наиболее молодых животных определенного типа в начале списка,
выполните следующий запрос:
mysql> SELECT name, species, birth FROM pet ORDER BY species, birth DESC;
Обратите внимание: действие ключевого слова DESC распространяется только на
тот столбец, имя которого располагается в запросе прямо перед этим словом (в
данном случае – birth); значения поля «species» по-прежнему отсортированы в
возрастающем порядке.
Задание 10. Вычисление дат
1. Определите возраст каждого из животных. Это можно сделать, если вычислить
разницу между текущим годом и годом его рождения, а из результата вычесть
единицу, если текущий день находится к началу календаря ближе, чем день
рождения животного. Приведенный ниже запрос выводит дату рождения каждого
животного, его возраст и текущую дату.
mysql> SELECT name, birth, CURRENT_DATE,
-> (YEAR(CURRENT_DATE)-YEAR(birth))
-> - (RIGHT(CURRENT_DATE,5)<RIGHT(birth,5))
7
-> AS age FROM pet;
В этом примере функция YEAR() выделяет из даты год, а RIGHT() – пять крайних
справа символов, представляющих календарный день (MM-DD). Часть выражения,
сравнивающая даты, выдает 1 или 0, что позволяет уменьшить результат на
единицу, если текущий день (CURRENT_DATE) находится к началу календаря
ближе, нежели день рождения животного. Вместо этого выражения в заголовке
соответствующего столбца результатов будем выводить псевдоним (age –
«возраст»).
2. Отсортируйте полученный результат по имени:
mysql> SELECT name, birth, CURRENT_DATE,
-> (YEAR(CURRENT_DATE)-YEAR(birth))
-> - (RIGHT(CURRENT_DATE,5)<RIGHT(birth,5))
-> AS age
-> FROM pet ORDER BY name;
3. Отсортируйте полученный результат по возрасту:
mysql> SELECT name, birth, CURRENT_DATE,
-> (YEAR(CURRENT_DATE)-YEAR(birth))
-> - (RIGHT(CURRENT_DATE,5)<RIGHT(birth,5))
-> AS age
-> FROM pet ORDER BY age;
4. Определите возраст, которого достигли умершие животные на момент смерти.
Выделить умерших животных можно, проверив значение поля death на предмет
равенства NULL. Затем для записей, значения поля death которых не равно NULL,
можно вычислить разницу между датами смерти и рождения:
mysql> SELECT name, birth, death,
-> (YEAR(death)-YEAR(birth)) - (RIGHT(death,5)<RIGHT(birth,5))
-> AS age
-> FROM pet WHERE death IS NOT NULL ORDER BY age;
5. Убедитесь, что в этом запросе вместо выражения death IS NOT NULL не может
быть использовано death <> NULL, так как NULL – особое значение.
8
6. Определите, дни рождения каких животных наступят в следующем месяце. Для
таких расчетов день и год значения не имеют; из столбца, содержащего дату
рождения, нас интересует только месяц. В MySQL предусмотрено несколько
функций для получения частей дат – YEAR(), MONTH(), и DAYOFMONTH().
Увидеть работу функции MONTH() можно с помощью простого запроса,
выводящего дату рождения birth и MONTH(birth):
mysql> SELECT name, birth, MONTH(birth) FROM pet;
Найд?м животных, дни рождения которых наступят в следующем месяце.
Предположим, что сейчас апрель. Тогда номер текущего месяца – 4, а искать надо
животных, родившихся в мае (5-м месяце), таким образом:
mysql> SELECT name, birth FROM pet WHERE MONTH(birth) = 5;
Однако в декабре возникают некоторые осложнения. Если просто добавить единицу
к номеру месяца (12) и поискать животных, родившихся в тринадцатом месяце,
найти ничего не удастся. Вместо этого нужно искать животных, родившихся в
январе (1-м месяце).
Создадим запрос, который будет работать вне зависимости от того, какой сейчас
месяц. Функция DATE_ADD() позволяет прибавить к дате некоторый интервал
времени. Если добавить к значению, возвращаемому функцией NOW(), месяц, а
затем извлечь из получившейся даты номер месяца при помощи функции MONTH(),
мы получим именно тот месяц, который нам нужен:
mysql>
SELECT
name,
birth
FROM
pet
WHERE
MONTH(birth)
=
MONTH(DATE_ADD(NOW(), INTERVAL 1 MONTH));
Ту же задачу можно решить и другим методом. Для этого нужно прибавить единицу
к номеру месяца, следующего за текущим (воспользовавшись функцией расчета по
модулю (MOD) для перехода к 0, если номер текущего месяца равен 12):
mysql> SELECT name, birth FROM pet
-> WHERE MONTH(birth) = MOD(MONTH(NOW()), 12) + 1;
Функция MONTH возвращает число от 1 до 12, а выражение MOD(число,12) –
число от 0 до 11. Поэтому операцию сложения нужно проводить после MOD(),
иначе результат «перепрыгнет» с ноября (11) сразу на январь (1).
9
Задание 11. Сравнение по шаблонам
1. Найдите все имена, начинающиеся с «b»:
mysql> SELECT * FROM pet WHERE name LIKE "b%";
2. Найдите все имена, заканчивающиеся на «fy»:
mysql> SELECT * FROM pet WHERE name LIKE "%fy";
3. Найдите все имена, содержащие «w»:
mysql> SELECT * FROM pet WHERE name LIKE "%w%";
4. Найдите все имена, содержащие ровно пять символов, при помощи шаблонного
символа «_»:
mysql> SELECT * FROM pet WHERE name LIKE "_____";
Задание 12. Подсчет строк
1. Узнайте при помощи функции COUNT(), сколько животных принадлежит
каждому из владельцев:
mysql> SELECT owner, COUNT(*) FROM pet GROUP BY owner;
2. Обратите внимание на использование команды GROUP BY для объединения всех
записей по каждому из владельцев. Убедитесь, что без этой команды запрос выдал
бы только сообщение об ошибке:
mysql> SELECT owner, COUNT(owner) FROM pet;
3. Подсчитайте количество животных каждого вида:
mysql> SELECT species, COUNT(*) FROM pet GROUP BY species;
4. Подсчитайте количество животных каждого пола:
mysql> SELECT sex, COUNT(*) FROM pet GROUP BY sex;
(в этой таблице результатов NULL обозначает, что пол животного неизвестен)
5. Подсчитайте количество животных каждого вида с учетом пола:
mysql> SELECT species, sex, COUNT(*) FROM pet GROUP BY species, sex;
6. При использовании функции COUNT() вовсе не обязательно загружать всю
таблицу. Например, предыдущий запрос, в котором учитываются только кошки и
собаки, выглядит следующим образом:
mysql> SELECT species, sex, COUNT(*) FROM pet
10
-> WHERE species = "dog" OR species = "cat"
-> GROUP BY species, sex;
7. Узнайте количество животных каждого пола с учетом только тех экземпляров,
пол которых известен:
mysql> SELECT species, sex, COUNT(*) FROM pet WHERE sex IS NOT NULL
-> GROUP BY species, sex;
Задание 13. Использование нескольких таблиц
1. Создайте таблицу событие (event), содержащую дополнительную информацию о
животных (записи о событиях наподобие посещения ветеринара или рождения
потомства). Эта таблица должна содержать:
? имена животных, чтобы знать, к какому животному относится какое событие;
? дату события;
? поле для описания события;
? поле, отражающее тип события, для распределить их по категориям.
mysql> CREATE TABLE event (name VARCHAR(20), date DATE,
-> type VARCHAR(15), remark VARCHAR(255));
Как и в случае с таблицей pet, начальные данные в таблицу проще всего загрузить,
создав текстовый файл с информацией, разделенной символами табуляции:
name
date
type
remark
Fluffy
1995-05-15
litter
4 kittens, 3 female, 1 male
Buffy
1993-06-23
litter
5 puppies, 2 female, 3 male
Buffy
1994-06-19
litter
3 puppies, 3 female
Chirpy
1999-03-21
vet
needed beak straightened
Slim
1997-08-03
vet
broken rib
Bowser
1991-10-12
kennel
Fang
1991-10-12
kennel
Fang
1998-08-28
birthday
Gave him a new chew toy
Claws
1998-03-17
birthday
Gave him a new flea collar
Whistler
1998-12-09
birthday
First birthday
Создайте соответствующий запрос.
11
2. Узнайте, в каком возрасте животные давали приплод. В таблице event указаны
даты рождения потомства, но для того, чтобы рассчитать возраст матери, нужно
знать и дату е? рождения. Так как даты рождения хранятся в таблице pet, в этом
запросе нужно использовать обе таблицы:
mysql> SELECT pet.name,
-> (TO_DAYS(date) - TO_DAYS(birth))/365 AS age, remark
-> FROM pet, event
-> WHERE pet.name = event.name AND type = "litter";
3. Для объединения не обязательно иметь две отдельные таблицы; иногда можно
объединить таблицу с самой собой – если нужно сравнить одни записи таблицы с
другими записями той же таблицы. Например, для того, чтобы обнаружить среди
животных «семейные пары», можно объединить таблицу pet с ней самой, составив
пары животных разного пола, но одного вида:
mysql> SELECT p1.name, p1.sex, p2.name, p2.sex, p1.species
-> FROM pet AS p1, pet AS p2
-> WHERE p1.species = p2.species AND p1.sex = "f" AND p2.sex = "m";
В этом запросе мы указываем псевдонимы имен таблицы, для обращения к столбцам
и определения, к какой из таблиц относится каждая ссылка на столбец.
12
